
💡Máte podezření, že problémy s JavaScriptem mohou blokovat zobrazení vaší stránky nebo části obsahu ve vyhledávání Google? Přečtěte si, jak odstranit problémy související s JavaScriptem pomocí průvodce řešením problémů společnosti Google.
JavaScript je důležitou součástí webové platformy, protože poskytuje mnoho funkcí, které z webu dělají výkonnou aplikační platformu. Zpřístupnění vašich webových aplikací založených na JavaScriptu prostřednictvím vyhledávače Google vám může pomoci najít nové uživatele a znovu zapojit stávající uživatele, kteří hledají obsah, který vaše webová aplikace poskytuje. Ačkoli vyhledávání Google Search pracuje v JavaScriptu se stále zelenou verzí Chromium, existuje několik věcí, které můžete optimalizovat.
Tato příručka popisuje, jak Google Search zpracovává JavaScript a přináší osvědčené postupy pro vylepšení webových aplikací v JavaScriptu pro Google Search.
Jak Google zpracovává JavaScript
Google zpracovává webové aplikace v jazyce JavaScript ve třech hlavních fázích:
- Procházení (Crawling)
- Vykreslování (Rendering)
- Indexování (Indexing)
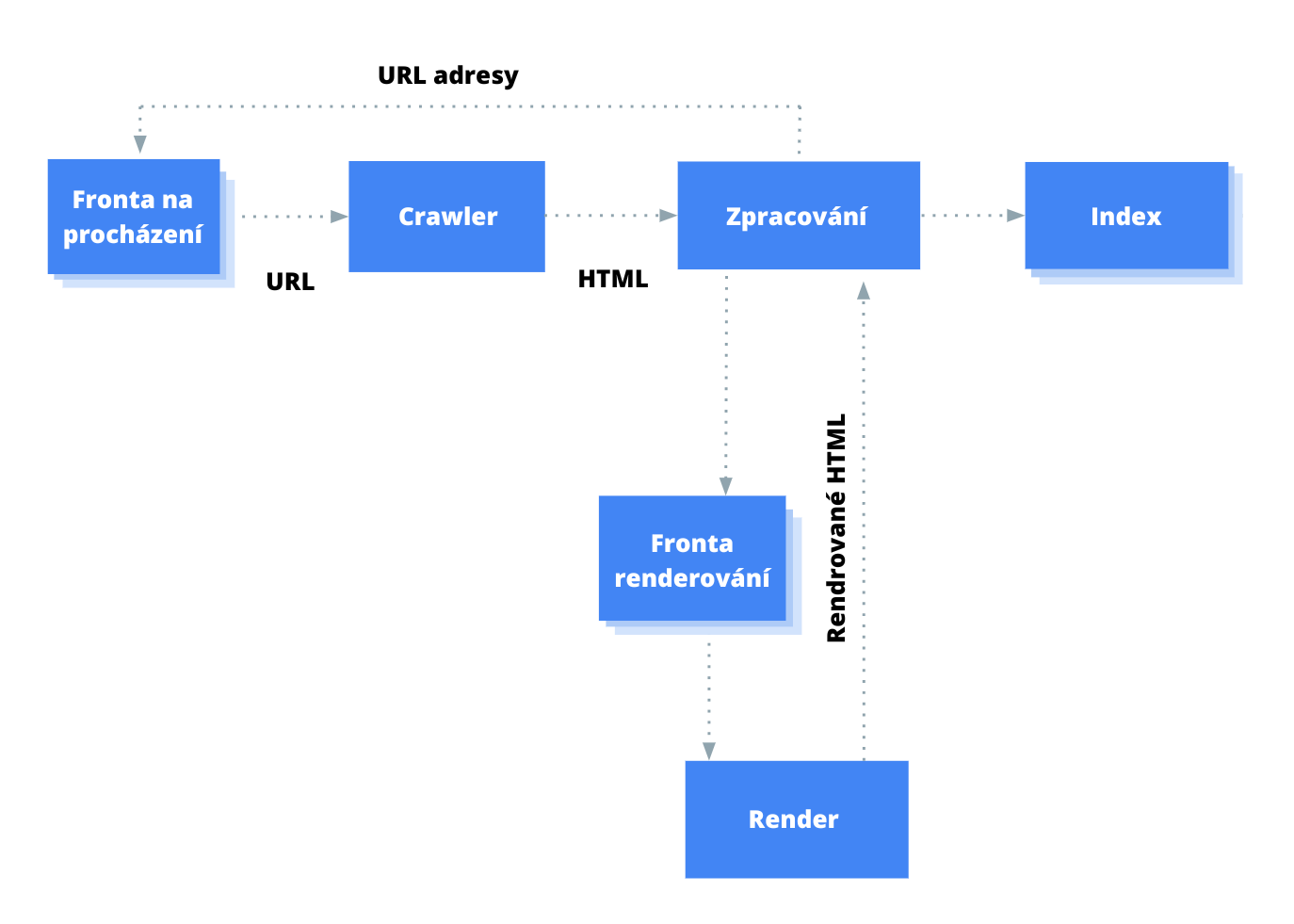
Googlebot řadí stránky do fronty pro procházení i vykreslování. Není hned zřejmé, kdy stránka čeká na procházení a kdy na vykreslení.
Když Googlebot načte adresu URL z fronty procházení požadavkem HTTP, nejprve zkontroluje, zda je procházení povoleno. Googlebot čte soubor robots.txt. Pokud označí adresu URL jako nepovolenou (disallowed), Googlebot vynechá provedení požadavku HTTP na tuto adresu URL a přeskočí ji.
Poté Googlebot analyzuje odpověď na další adresy URL v atributu href odkazů HTML a přidá tyto adresy URL do fronty procházení. Chcete-li zabránit zjišťování odkazů, použijte mechanismus nofollow.
★ K vložení odkazů do DOM je možné použít JavaScript, pokud tyto odkazy dodržují osvědčené postupy pro procházení odkazů.
Procházení adresy URL a rozbor odpovědi HTML funguje dobře u klasických webových stránek nebo stránek vykreslovaných na straně serveru, kde HTML v odpovědi HTTP zahrnuje veškerý obsah. Některé stránky s JavaScriptem mohou používat model App Shell, kde počáteční HTML nezahrnuje skutečný obsah a Google musí spustit JavaScript, než je schopen zobrazit skutečný obsah stránky, který JavaScript generuje.
Googlebot zařadí všechny stránky do fronty pro vykreslení, pokud meta značka robots nebo hlavička neříká, aby Google stránku neindexoval. Stránka může zůstat v této frontě několik sekund, ale může to trvat i déle. Jakmile to zdroje Google dovolí, Chromium stránku vykreslí a spustí JavaScript. Googlebot znovu analyzuje vykreslený HTML pro odkazy a nalezené adresy URL zařadí do fronty pro procházení. Google také použije vykreslený HTML k indexování stránky.
Mějte na paměti, že vykreslování na straně serveru nebo předběžné vykreslování je stále skvělý nápad, protože díky němu jsou vaše webové stránky rychlejší pro uživatele i pro procházení a navíc ne všichni roboti mohou spouštět JavaScript.
Popište svou stránku pomocí jedinečných názvů a úryvků
Jedinečné popisné prvky <title> a užitečné meta descriptiony pomáhají uživatelům rychle najít nejlepší odpověď na jejich dotaz.
Pomocí JavaScriptu můžete nastavit nebo změnit meta description i prvek <title>.
Vyhledávač Google může na základě dotazu uživatele ve výsledcích vyhledávání zobrazit jiný title. K tomu dochází v případě, že title nebo meta popisek mají nízkou relevanci k obsahu stránky nebo když Google na stránce našel alternativy, které lépe odpovídají vyhledávacímu dotazu.
Napište kompatibilní kód
Prohlížeče nabízejí mnoho rozhraní API a jazyk JavaScript se rychle vyvíjí. Společnost Google má určitá omezení týkající se toho, která rozhraní API a funkce jazyka JavaScript podporuje. Chcete-li se ujistit, že je váš kód kompatibilní se službou Google, postupujte podle našich pokynů pro řešení problémů s JavaScriptem.
Pokud zjistíte chybějící rozhraní API prohlížeče, které potřebujete, doporučujeme použít diferenciální obsluhu a polyfill. Vzhledem k tomu, že některé funkce prohlížeče nelze polyfillovat, doporučujeme zkontrolovat dokumentaci k polyfillu, zda neobsahuje případná omezení.
Používání smysluplných stavových kódů HTTP
Googlebot používá stavové kódy HTTP, aby zjistil, zda se při procházení stránky něco pokazilo.
Chcete-li robotovi Googlebot sdělit, že stránku nelze procházet nebo indexovat, použijte smysluplný stavový kód, například 404 pro stránku, kterou se nepodařilo najít, nebo kód 401 pro stránky za přihlášením. Pomocí stavových kódů HTTP můžete robotovi Googlebot sdělit, že se stránka přesunula na novou adresu URL, aby mohl být index odpovídajícím způsobem aktualizován.
Zde je seznam stavových kódů HTTP a jejich vliv na vyhledávání Google.
Vyhněte se chybám soft 404 v jednostránkových aplikacích
V jednostránkových aplikacích vykreslovaných na straně klienta je směrování často implementováno jako směrování na straně klienta. V takovém případě může být použití smysluplných stavových kódů HTTP nemožné nebo nepraktické. Chcete-li se vyhnout chybám soft 404 při použití vykreslování a směrování na straně klienta, použijte jednu z následujících strategií:
- Použijte přesměrování JavaScript na adresu URL, na kterou server odpoví stavovým kódem HTTP 404 (například /not-found).
- Přidejte <meta name=”robots” content=”noindex”> na chybové stránky pomocí JavaScriptu.
Zde je ukázka kódu pro přístup přesměrování:
fetch(`/api/products/${productId}`) .then(response => response.json()) .then(product => { if(product.exists) { showProductDetails(product); // zobrazí informace o produktu na stránce } else { // tento produkt neexistuje, takže se jedná o chybovou stránku. window.location.href = '/not-found'; // přesměrování na stránku 404 na serveru. } })
Zde je ukázka kódu pro přístup se značkou noindex:
fetch(`/api/products/${productId}`) .then(response => response.json()) .then(product => { if(product.exists) { showProductDetails(product); // zobrazí informace o produktu na stránce } else { // tento produkt neexistuje, takže se jedná o chybovou stránku. // Poznámka: Tento příklad předpokládá, že v HTML není přítomen žádný jiný meta tag robots. const metaRobots = document.createElement('meta'); metaRobots.name = 'robots'; metaRobots.content = 'noindex'; document.head.appendChild(metaRobots); } })
Použití rozhraní API Historie místo fragmentů
Google může váš odkaz procházet pouze v případě, že se jedná o prvek <a> HTML s atributem href.
U jednostránkových aplikací se směrováním na straně klienta použijte rozhraní API Historie k implementaci směrování mezi různými zobrazeními webové aplikace. Chcete-li zajistit, aby robot Google mohl analyzovat a extrahovat vaše adresy URL, vyhněte se používání fragmentů pro načítání různého obsahu stránek. Následující příklad je špatný postup, protože Googlebot nemůže spolehlivě rozluštit adresy URL:
<nav> <ul> <li><a href="#/products">Our products</a></li> <li><a href="#/services">Our services</a></li> </ul> </nav> <h1>Vítejte na example.com!</h1> <div id="placeholder"> <p>Další informace o <a href="#/products">našich produktech</a> a <a href="#/services">našich službách</p> </div> <script> window.addEventListener('hashchange', function goToPage() { // tato funkce načte jiný obsah na základě aktuálního fragmentu adresy URL const pageToLoad = window.location.hash.slice(1); // Fragment adresy URL document.getElementById('placeholder').innerHTML = load(pageToLoad); }); </script>
Místo toho můžete zajistit, aby vaše adresy URL byly přístupné pro Googlebot, a to implementací rozhraní API Historie:
<nav> <ul> <li><a href="/products">Naše produkty</a></li> <li><a href="/services">Naše služby</a></li> </ul> </nav> <h1>Vítejte na example.com!</h1> <div id="placeholder"> <p>Další informace o <a href="/products">našich produktech</a> a <a href="/services">našich službách</p> </div> <script> function goToPage(event) { event.preventDefault(); // zastaví prohlížeč v navigaci na cílovou adresu URL. const hrefUrl = event.target.getAttribute('href'); const pageToLoad = hrefUrl.slice(1); // odstranění úvodního lomítka document.getElementById('placeholder').innerHTML = load(pageToLoad); window.history.pushState({}, window.title, hrefUrl) // Aktualizace URL a historie prohlížeče. } // Povolení směrování na straně klienta pro všechny odkazy na stránce document.querySelectorAll('a').forEach(link => link.addEventListener('click', goToPage)); </script>
Správné vložení značky odkazu rel=”canonical”
Přestože nedoporučujeme používat k tomuto účelu JavaScript, je možné značku rel=”canonical” odkazu pomocí JavaScriptu injektovat. Vyhledávač Google při vykreslování stránky zachytí injektovanou kanonickou adresu URL. Zde je příklad injektování značky rel=”canonical” odkazu pomocí JavaScriptu:
fetch('/api/cats/' + id)
.then(function (response) { return response.json(); })
.then(function (cat) {
// vytvoří kanonickou značku odkazu a dynamicky sestaví adresu URL
// např. https://example.com/cats/simba
const linkTag = document.createElement('link');
linkTag.setAttribute('rel', 'canonical');
linkTag.href = 'https://example.com/cats/' + cat.urlFriendlyName;
document.head.appendChild(linkTag);
});
❗Při použití JavaScriptu k vložení značky rel=”canonical” odkazu se ujistěte, že se jedná o jedinou značku rel=”canonical” odkazu na stránce. Nesprávná implementace může vytvořit více značek odkazu rel=”canonical” nebo změnit stávající značku odkazu rel=”canonical”. Konfliktní nebo vícenásobné značky odkazu rel=”canonical” mohou vést k neočekávaným výsledkům.
Meta tagy robots používejte opatrně
Pomocí meta tagu robots můžete zabránit Googlu v indexování stránky nebo sledování odkazů. Například přidáním následující metaznačky na začátek stránky zablokujete indexování stránky společností Google:
<!-- Google nebude tuto stránku indexovat ani sledovat odkazy na této stránce --> <meta name="robots" content="noindex, nofollow">
Pomocí JavaScriptu můžete na stránku přidat metaznačku robots nebo změnit její obsah. Následující příklad kódu ukazuje, jak pomocí JavaScriptu změnit metaznačku robots, aby se zabránilo indexování aktuální stránky, pokud volání API nevrátí obsah.
fetch('/api/products/' + productId)
.then(function (response) { return response.json(); })
.then(function (apiResponse) {
if (apiResponse.isError) {
// získejte meta tag robots
var metaRobots = document.querySelector('meta[name="robots"]');
// pokud metaznačka robots neexistuje, přidejte ji.
if (!metaRobots) {
metaRobots = document.createElement('meta');
metaRobots.setAttribute('name', 'robots');
document.head.appendChild(metaRobots);
}
// řekněte společnosti Google, aby tuto stránku vyloučila z indexu
metaRobots.setAttribute('content', 'noindex');
// zobrazte uživateli chybovou zprávu
errorMsg.textContent = 'Tento produkt již není k dispozici';
return;
}
// zobrazit informace o produktu
// ...
});
Pokud Google před spuštěním JavaScriptu narazí na noindex v meta tagu robots, stránku nezobrazí ani nezaindexuje.
❗Pokud Google narazí na značku noindex, přeskočí vykreslování a spouštění JavaScriptu. Protože Google v tomto případě přeskočí váš JavaScript, nemá šanci značku ze stránky odstranit.
Použití JavaScriptu ke změně nebo odstranění metaznačky robots nemusí fungovat podle očekávání. Google přeskočí vykreslování a spuštění JavaScriptu, pokud metaznačka robots původně obsahuje noindex. Pokud existuje možnost, že chcete stránku indexovat, nepoužívejte v původním kódu stránky značku noindex.
Použití dlouhodobého ukládání do mezipaměti
Googlebot agresivně ukládá do mezipaměti, aby snížil počet síťových požadavků a spotřebu prostředků. Systém WRS může ignorovat hlavičky mezipaměti. To může vést k tomu, že systém WRS bude používat zastaralé prostředky JavaScriptu nebo CSS. Otiskování obsahu tomuto problému předchází tím, že součástí názvu souboru je otisk obsahu, například main.2bb85551.js. Otisk závisí na obsahu souboru, takže aktualizace generují pokaždé jiný název souboru. Více informací najdete v příručce web.dev o strategiích dlouhodobého ukládání do mezipaměti.
Použití strukturovaných dat
Pokud na svých stránkách používáte strukturovaná data, můžete pomocí JavaScriptu vygenerovat požadovaný JSON-LD a vložit jej do stránky. Nezapomeňte implementaci otestovat, abyste se vyhnuli problémům.
Dodržování osvědčených postupů pro webové komponenty
Google podporuje webové komponenty. Při vykreslování stránky Google zploští stínový a světlý obsah DOM. To znamená, že Google vidí pouze obsah, který je viditelný ve vykresleném HTML. Chcete-li se ujistit, že Google vidí váš obsah i po vykreslení, použijte test Mobile-Friendly nebo nástroj pro kontrolu URL a podívejte se na vykreslený HTML.
Pokud obsah není ve vykresleném HTML viditelný, Google jej nebude moci indexovat.
Následující příklad vytváří webovou komponentu, která zobrazuje svůj lehký obsah DOM uvnitř svého stínového DOM. Jedním ze způsobů, jak zajistit, aby se ve vykresleném HTML zobrazil jak světlý, tak stínový obsah DOM, je použití prvku Slot.
<script> class MyComponent extends HTMLElement { constructor() { super(); this.attachShadow({ made: 'open' }); } connectCallback() { letp = document.createElement( 'p' ); p.innerHTML = 'Ahoj světe, toto je shadow DOM obsah. Zde přichází light DOM: <slot></slot>'; this.shadowRoot.appendChild(p); } } window.customElements.define('my-component', MyComponent); </script> <my-component> <p>Toto je light DOM obsah. Promítá se do shadow DOM.</p> <p>WRS vykresluje tento obsah i shadow DOM obsah.</p> <my-component>
Po vykreslení může Google tento obsah indexovat:
<my-component> Hello World, toto je stínový obsah DOM. Zde přichází světelný DOM: <p>Toto je lehký obsah DOM. Promítá se do stínového DOM<p> <p>WRS vykreslí tento obsah stejně jako stínový obsah DOM.</p> </my-component>
Oprava obrázků a líně načteného obsahu
Obrázky mohou být poměrně nákladné na šířku pásma a výkon. Dobrou strategií je použití líného načítání, kdy se obrázky načítají pouze v okamžiku, kdy je má uživatel vidět. Chcete-li se ujistit, že lazy-loading implementujete způsobem, který je vhodný pro vyhledávání, řiďte se našimi pokyny pro lazy-loading.
Design pro přístupnost
Vytvářejte stránky pro uživatele, nejen pro vyhledávače. Při navrhování webu myslete na potřeby uživatelů, včetně těch, kteří nemusí používat prohlížeč podporující JavaScript (například lidé, kteří používají čtečky obrazovky nebo méně pokročilá mobilní zařízení). Jedním z nejjednodušších způsobů, jak otestovat přístupnost webu, je zobrazit jeho náhled v prohlížeči s vypnutým JavaScriptem nebo si ho prohlédnout v textovém prohlížeči, jako je například Lynx. Zobrazení webu pouze jako textového vám také pomůže identifikovat další obsah, který může být pro Google obtížně viditelný, například text vložený do obrázků.
Překlad, odborná a obsahová korektura: SEOPRAKTICKY.CZ
Použité zdroje
- Understand JavaScript SEO Basics | Google Search Central | Documentation | Google for Developers. Google for Developers – from AI and Cloud, to Mobile and Web [online]. Dostupné z: https://developers.google.com/search/docs/crawling-indexing/javascript/javascript-seo-basics
Související články
Procházení a indexování
- Mapy stránek
- Správa crawlingu
- Robots.txt
- Kanonizace
- Mobilní web a indexování podle mobilních zařízení
- AMP
- JavaScript
- Pochopení základů SEO v JavaScriptu
- Oprava problémů souvisejících s vyhledáváním v JavaScriptu
- Oprava lazy-loaded obsahu
- Dynamické vykreslování jako řešení
Ranking a možnosti zobrazení ve výsledku vyhledávání
Monitorování a odstraňování chyb
Průvodce pro konkrétní stránky
