
Nastavení souboru robots.txt nikdy nedělejte, pokud si nejste absolutně jisti, co děláte. Jeho špatné nastavení může způsobit chybné procházení a tím pádem i indexaci vašich stránek!
Standard robots.txt (angl. Robots Exclusion Standard nebo též Robots Exclusion Protocol) slouží správcům webových stránek k předepsání žádaného chování robotů k webu.
Používá se v případech, kdy stránka nebo část webu je funkční a přístupná pro lidi, ale robotům je potřeba stahování obsahu zakázat (např. podstránky pro administraci webu, placené články ve zpravodajských archivech, interní diskuzní fóra, výsledky vyhledávání v e-shopu apod.).
Soubor slouží ke sdělení záměru správce webu a ulehčení vzájemné komunikace; čtení a respektování uvedených pravidel je zcela na rozhodnutí robota, který na web přijde.
Pokud robots.txt existuje, což není podmínka pro správné fungování stránek, najdete ho vždy v kořenovém adresáři vaší stránky a vždy má formu textového dokumentu s názvem robots.txt.
Na každém e-shopu na Shoptetu se můžete podívat tak, že za doménu zadáte robots.txt:
www.vasedomena.cz/robots.txt
Syntaxe robots.txt
User-agent:
Instrukce, které předáváte specificky pro některého crawlera. Chcete-li aplikovat na všechny, použijte symbol hvězdičky (*).
Chcete-li direktivu aplikovat pouze pro některého bota, musíte vypsat jeho název.
Některé systémy mohou mít více botů, každý z nich pak crawluje specifické části stránek. Google například používá Googlebot pro organické vyhledávání a Googlebot-Image pro vyhledávání obrázků.
Setkat se můžete také s mobilním botem nebo botem reklamního systému.
Seznam většiny botů najdete na stránce https://www.robotstxt.org/db.html
User-agent: * (direktiva platí pro všechny boty)
User-agent: Googlebot (direktiva platí pouze pro bota Googlu)
Disallow:
Příkaz používaný k tomu, aby crawler neprocházel konkrétní URL nebo sekci. Pro každou direktivu URL nebo adresáře je možné použít jenom jeden řádek.
Direktiva níže platí pro Googlebota a zakazuje mu procházet celý blog.
User-agent: Googlebot
Disallow: /blog/
Allow:
Příkaz informující Googlebota (tento příkaz je použitelný jen pro Googlebota), že má přístup na stránku nebo podsložku, i když může být její nadřazená stránka nebo podsložka zakázána.
Níže je uveden příklad, v němž má Googlebot zakázaný přístup do blogu s výjimkou všech stránek v kategorii Nové články.
User-agent: Googlebot
Disallow: /blog/
Allow: /blog/nove-clanky/
Crawl-delay:
Direktiva, kterou botům určujete, kolik sekund se má čekat před načtením a procházením dalšího obsahu. Googlebot tento příkaz nerespektuje, ale rychlost procházení lze nastavit v Google Search Console.
Z mého pohledu nadužívaná direktiva, kterou boti vesele ignorují. Často se používá ve snaze nepřetěžovat server stránek.
User-agent: Googlebot
Crawl-delay: 5
Sitemap:
Odkaz na mapu stránek, které zpravidla chceme indexovat.
Tento příkaz je podporován pouze společnostmi Google, Seznam, Ask, Bing a Yahoo.
User-agent: *
Sitemap: https://www.vasedomena.cz/sitemap.xml
Je nutné v robots.txt odkazovat na sitemapu?
Možná si kladete otázku, jestli je nutné z robots.txt odkazovat na sitemapu.
Pokud máte sitemapu navedenou v Google Search Console, není nutní na ni z robots.txt odkazovat. Pro jiné boty ale význam mít bude. Nezapomínejte, že v Česku máme dalšího významného hráče, Seznam.cz. A minimálně pro toho je dobré sitemapu v robots.txt mít.
Pro každého bota nemusíte na sitemapu odkazovat zvlášť. Odkaz na ni stačí dát na začátek nebo na konec textového souboru.
Častý omyl fungování robots.txt
Na diskuzních fórech se velmi často setkávám s chybným doporučením, jak vyhledávačům zabránit v indexaci stránek.
Bohužel ani ti nejzkušenější SEO specialisté neznají tuto elementární věc a správcům webů radí chybně.
Robots.txt nezabraňuje indexaci stránek! Robots.txt brání vyhledávačům v procházení, nikoliv v indexaci. A to, že tam bot nemá přístup, ještě neznamená, že nedojde k indexaci stránky.
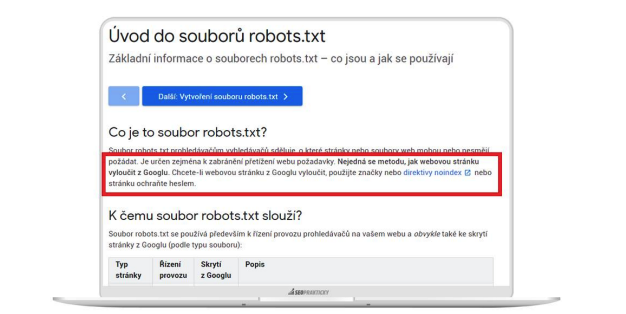
Chcete-li zabránit vyhledávačům v indexaci stránky, je nutné umístit direktivu do metahlavičky přímo na stránku, viz další kapitola.
Robots.txt v Shoptetu
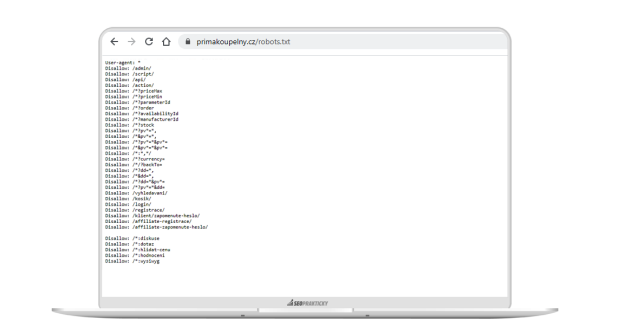
V Shoptetu se o informace v robots.txt starat nemusíte, dělá to za vás systém.
Pokud si robots.txt v Shoptetu neupravíte, vždy bude mít výchozí podobu, která vypadá takto:
I přesto mohou existovat případy, kdy se možnost editovat robots.txt hodí. A v Shoptetu ji máte.
Možnost vložit svůj kus kódu do robots.txt máte z VZHLED A OBSAH → Editor → HTML kód → Robots.txt.
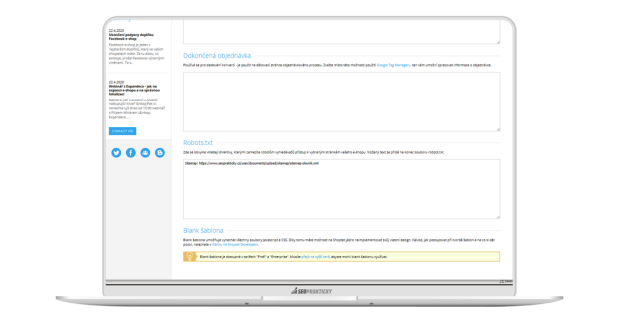
Do robots.txt si můžete například vložit sitemapu na stránky ze slovníku pojmů (které se do standardní sitemapy nevkládají) nebo třeba na sitemapu obrázků.
Když chcete najít všechny důležité informace o robots.txt na jednom místě – k čemu slouží soubor robots.txt, jak jej vytvořit, aktualizovat i jak pracovat se sitemapou robots.txt – tohle vše naleznete v přehledném článku Robots.txt: Kompletní průvodce, návod, tipy a rady.
