
Ve chvíli, kdy se rozhodnete pustit do analýzy klíčových slov, bude třeba připravit základní dataset s vhodnými výrazy. Ty následně můžete rozšířit o další související fráze, abyste měli zmapováno co nejvíce klíčových slov a jejich variací.
Jakmile svůj dataset obohatíte o další související fráze, budete mít k dispozici obsáhlý seznam slov, se kterým pak můžete nakládat dle potřeby. Z celého datasetu pak můžete vyfiltrovat např. pouze výrazy s určitou hledaností nebo výrazy vztahující se k nějaké kategorii, na níž jste se rozhodli zaměřit.
Osnova
Získání základního datasetu
Nejprve ověřte, na jaká klíčová slova se aktuálně zobrazuje váš web.
K tomu můžete využít analýzu Svatý grál. Jedná se o analýzu, která dokáže identifikovat klíčová slova na doméně, kterou zadáte. Tím téměř ihned získáte přehled o tom, na jaká klíčová slova se web aktuálně zobrazuje ve vyhledávání.
Svatý grál najdete v hlavičce aplikace – pod tlačítkem Analýzy a nástroje.
Zadejte doménu vašeho webu a pokračujte na výsledky.
Zobrazí se náhled výsledků -> pro kompletní výsledky pokračujte k nastavení analýzy.
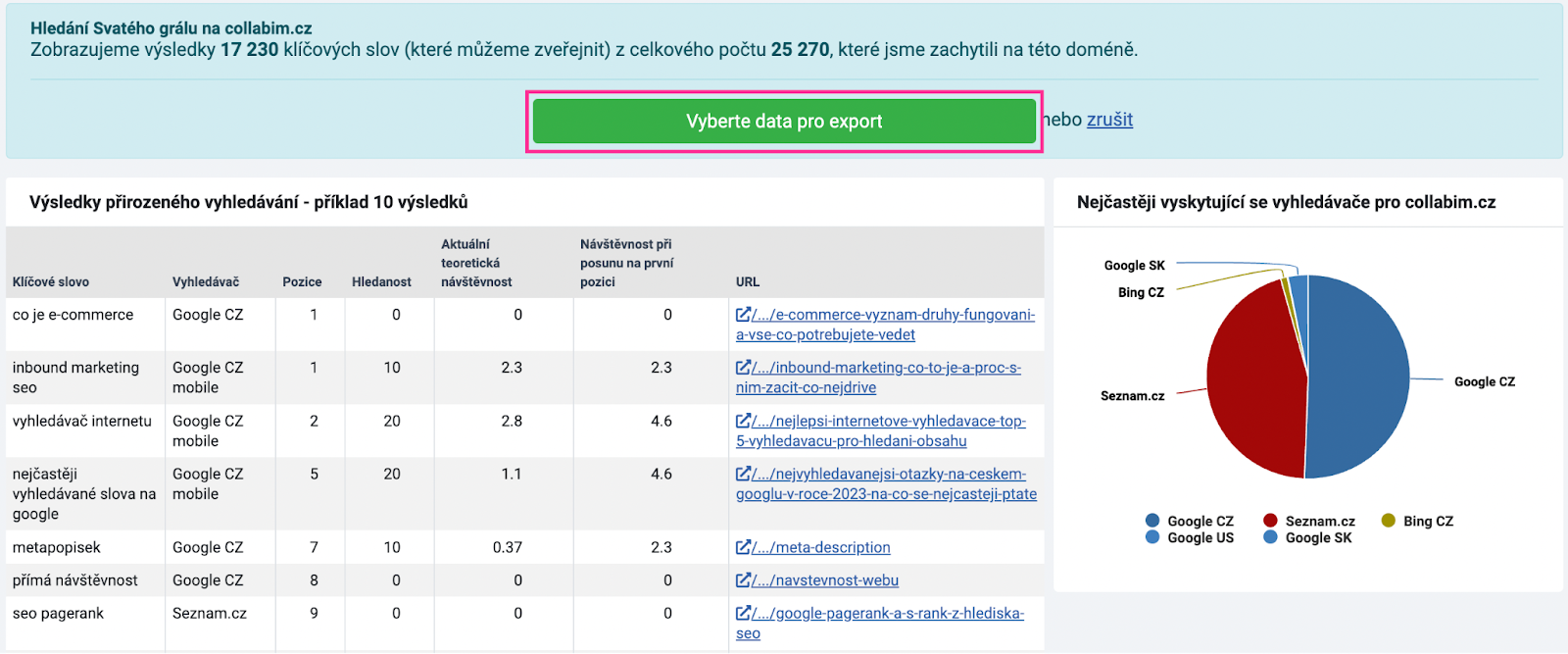
Zaškrtněte organické výsledky a spusťte analýzu.
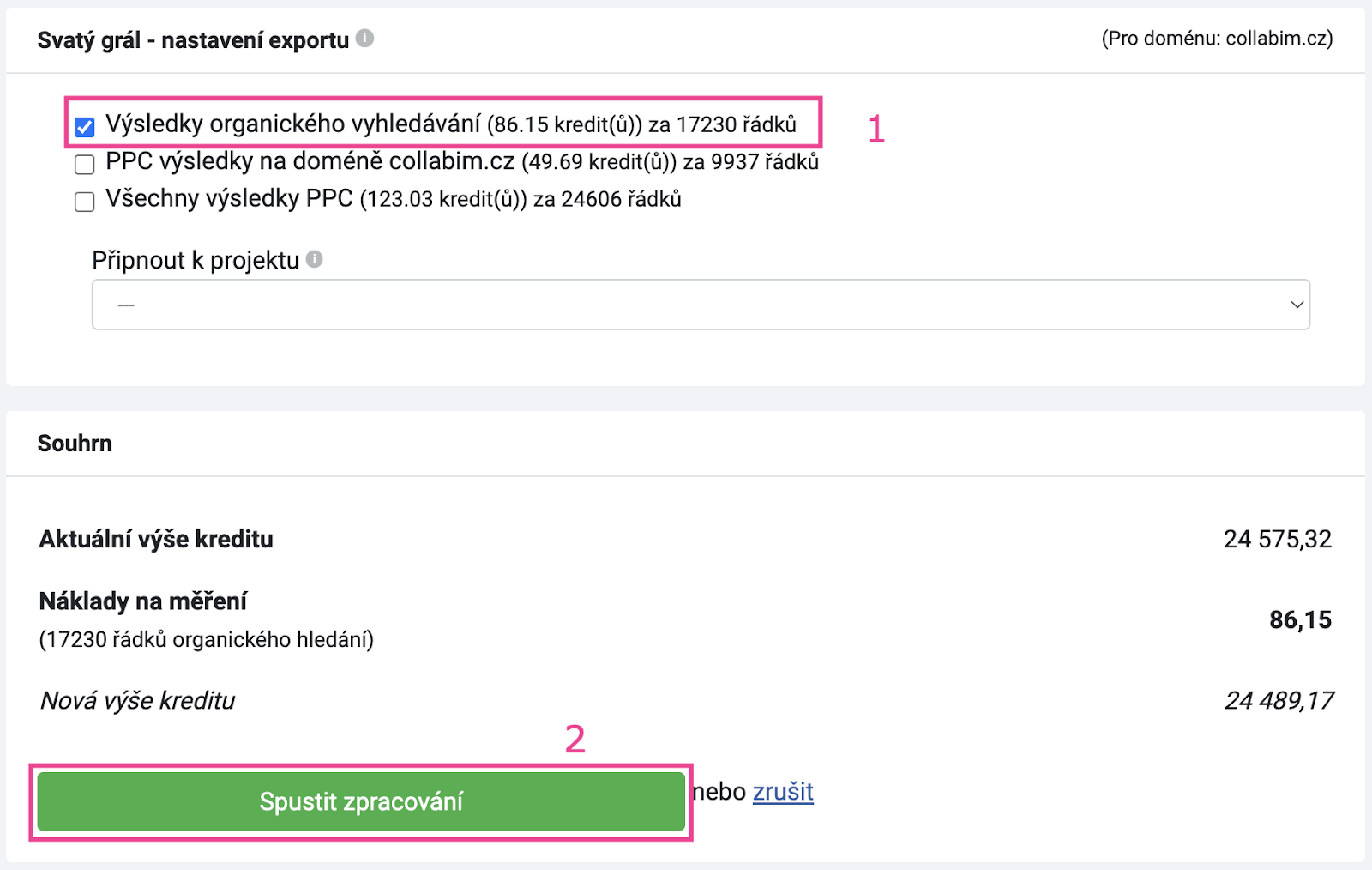
Jakmile analýza doběhne, stáhněte si výsledky do tabulky.

Tabulku si otevřete v Excelu, nebo Tabulkách Google. Vyberte záložku Organic results. Ostatní záložky můžete případně odstranit.
![]()
V tabulce uvidíte seznam klíčových slov, na která se váš web již nyní zobrazuje ve vyhledávání. Aktuálně vás zajímá pouze seznam frází (sloupečk “Keyword”). Ostatní sloupečky v rámci této tabulky potřebovat nebudete, můžete je proto smazat.
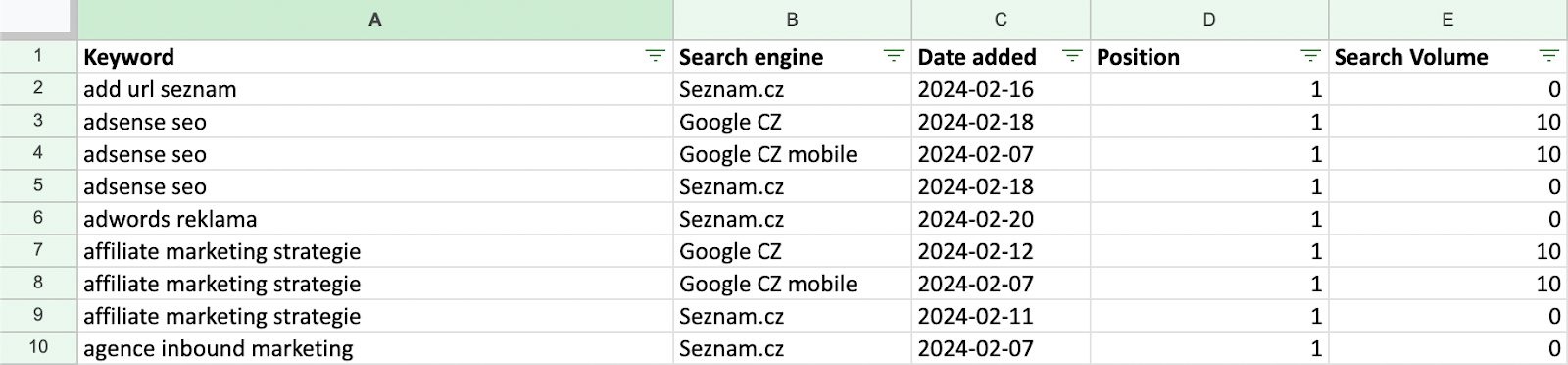
Rozšíření datasetu
Nyní svůj základní dataset můžete rozšířit o další klíčová slova, abyste měli co nejvíce vstupních dat. Dataset můžete obohatit o další fráze několika způsoby.
Analýza konkurence přes Svatý grál
Podobně jako v předešlém případě lze přes Svatý grál analyzovat i cizí domény. Můžete tak najít a získat klíčová slova konkurenčních webů. Konkurenty doporučujeme zvolit spíše silnější, aby srovnání bylo relevantní.
Pokud si přejete ověřit co nejvíce frází, nemusíte zůstávat jen u jednoho konkurenta. Analyzovat můžete i více konkurentů – postup je stejný jako v předchozím případě. Obvykle však nemá smysl ověřovat více než 4 konkurenty, protože s každým dalším konkurentem se zvyšuje šance, že získáte více méně totožné výrazy.
Obsah všech tabulek pak slučte do jedné (vždy jen sloupeček “Keyword”). Tak budete mít všechna klíčová slova (tedy slova vašeho webu a dalších konkurenčních webů) dohromady v jedné tabulce.
Sloučení tabulek
Nyní je třeba sloučit všechna klíčová slova do jedné tabulky.
Nejprve zrušte filtr ve svém datasetu. Poté, co tabulku aktualizujete o nové výrazy, můžete případně nastavit nový filtr.

Otevřete si export Svatého grálu konkurenční domény, označte si sloupeček s klíčovými slovy (“Keyword”) a všechen obsah sloupečku zkopírujte.
Přejděte zpět do svého datasetu. Je-li třeba, přidejte do tabulky nové řádky a vložte zkopírovaná klíčová slova na konec vašeho sloupečku “Keyword”.
Odstranění duplicit
Nyní se můžete pustit do očištění datasetu. V datasetu se totiž mohou nacházet duplicitní výrazy. Jednak proto, že už základní dataset může obsahovat stejná klíčová slova v rámci různých vyhledávačů, a jednak proto, že konkurent se může zobrazovat na stejné výrazy jako vy. Je tedy možné, že díky sloučení výsledků se v tabulce objevily duplicitní výrazy, které nejsou žádoucí.
Označte celý sloupec A (“Keyword”) a odstraňte duplicity. V Tabulkách Google toto provedete přes horní nabídku -> Data -> Vyčištění dat -> Odstranit duplicity.
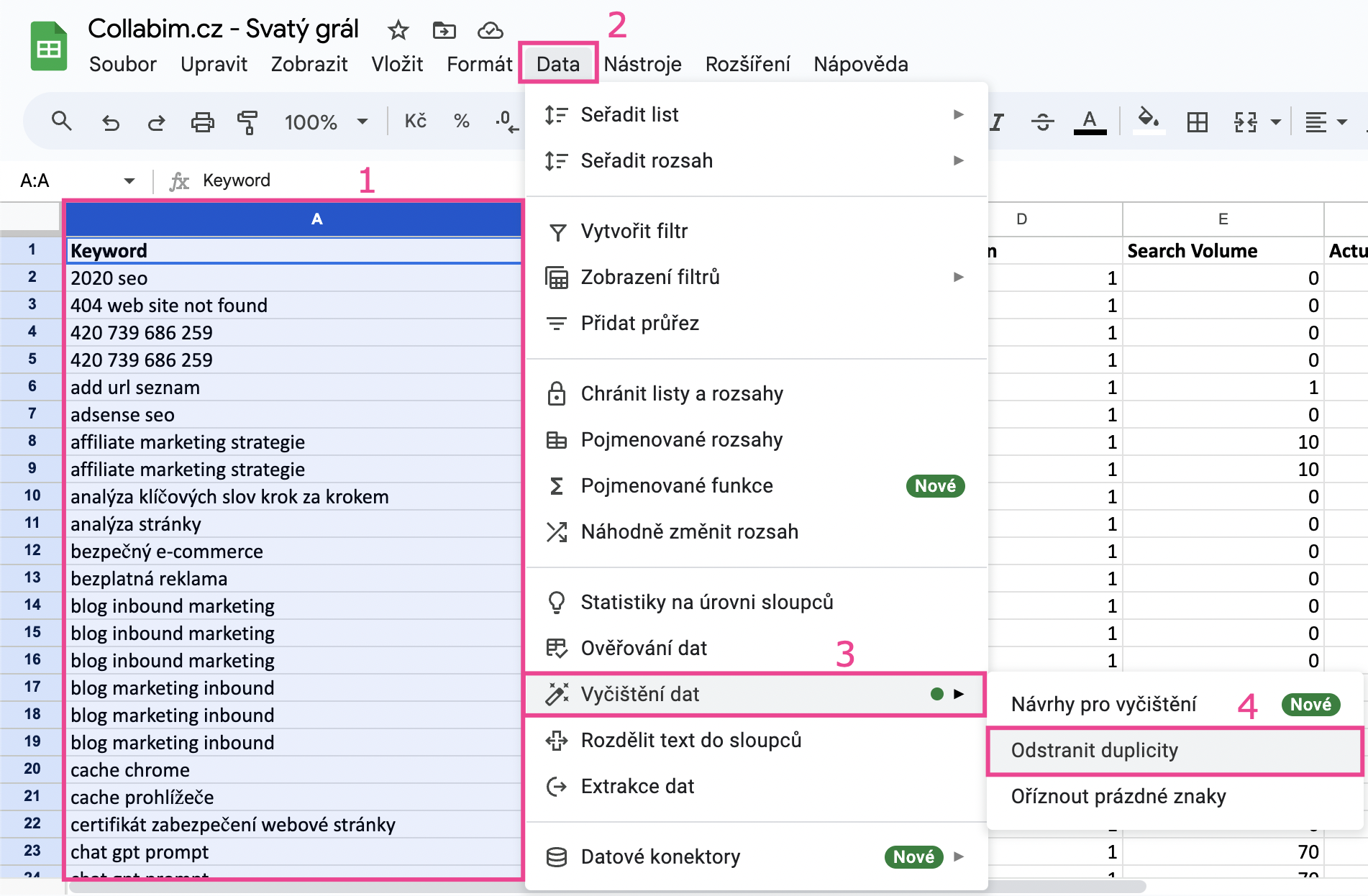
Poté jen potvrďte akci.
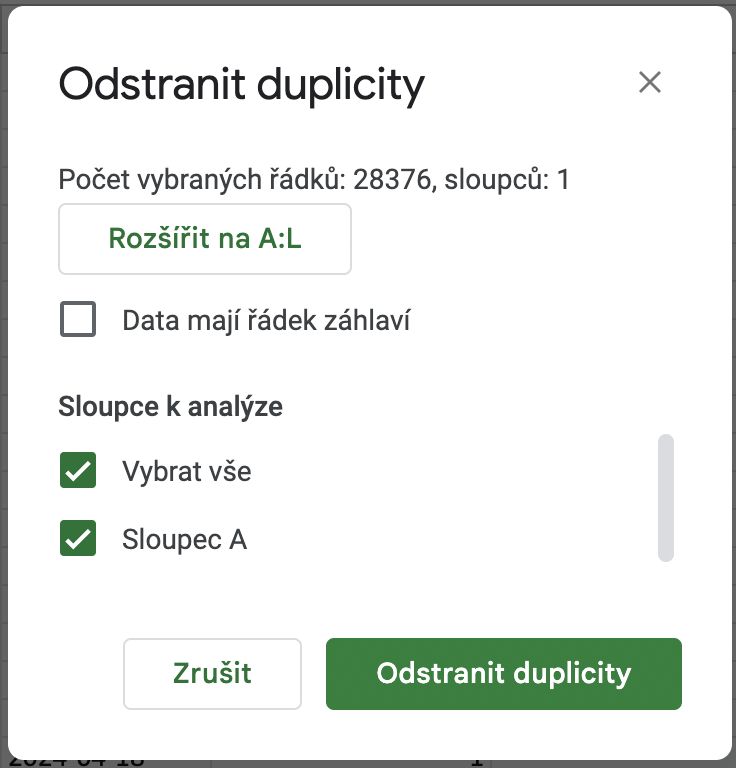
V našem případě – tím, že jsme odstranili duplicity – nám v datasetu zbylo necelých 13 tisíc z původních cca 28 tisíc klíčových slov a dataset nyní neobsahuje žádné duplicitní výrazy.
Odstranění prázdných řádků
Je možné, že po odstranění duplicit ve sloupečku vznikly prázdné řádky. Pro jistotu tedy prázdné řádky odfiltrujte.
Nejprve označte všechny buňky v tabulce (ctrl+A) a poté vytvořte nový filtr.

Jakmile budete mít filtr vytvořený, stačí kliknout na nastavení filtru v rohu sloupečku, u položky “Filtrovat dle podmínky” zvolit možnost “Není prázdné” a filtr potvrdit. Tím zmizí všechny prázdné řádky.
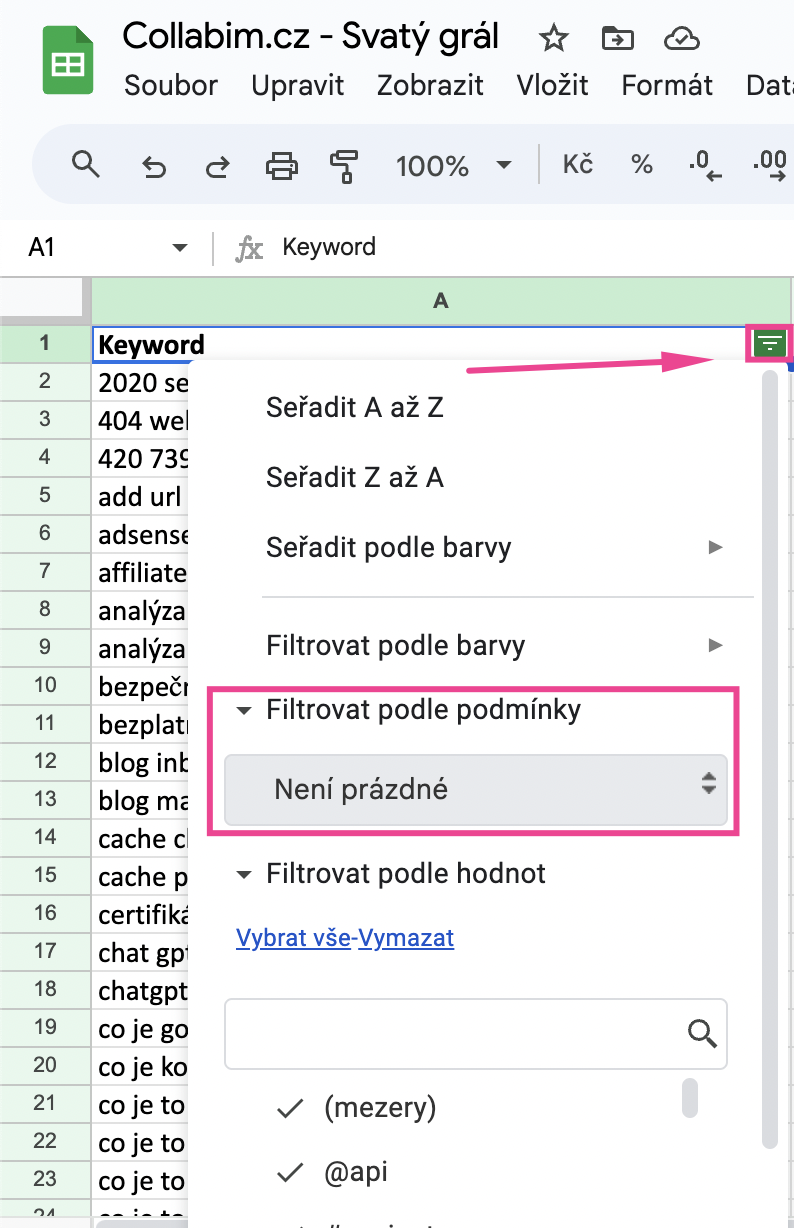
Filtr ovšem řádky pouze skryje. Proto vyfiltrovaný obsah zkopírujte a vložte do nového sloupečku vedle.
Postup:
- Označte celý sloupec A (“Keyword”)
- Zkopírujte obsah
- Zrušte filtr
- Vytvořte nový sloupeček B
- Vložte zkopírovaný obsah
- Sloupec A odstraňte
Tím se zbavíte prázdných řádků, aniž byste museli mít aktivovaný filtr.
Návrhy klíčových slov
Aktuální dataset můžete také rozšířit o související fráze, abyste získali širší pásmo klíčových slov. S tím vám pomůže jednorázová analýza Návrhy klíčových slov.
Nejprve si označte všechna klíčová slova ve vaší tabulce a slova zkopírujte.
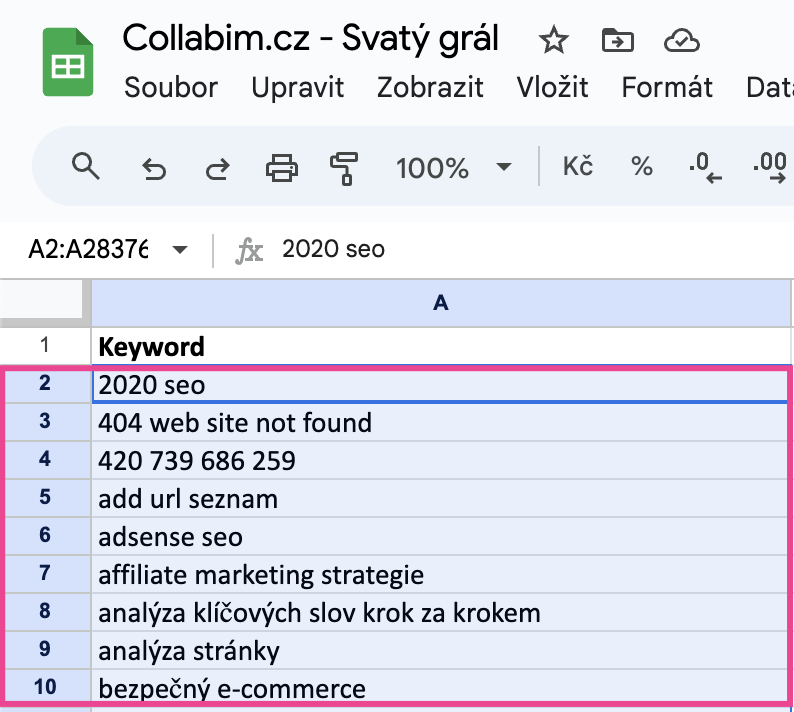
V hlavičce Collabimu klikněte na tlačítko Analýzy a nástroje a v nabídce vyberte Návrhy klíčových slov.
Vložte zkopírovaná slova do schránky a pokračujte na další krok.
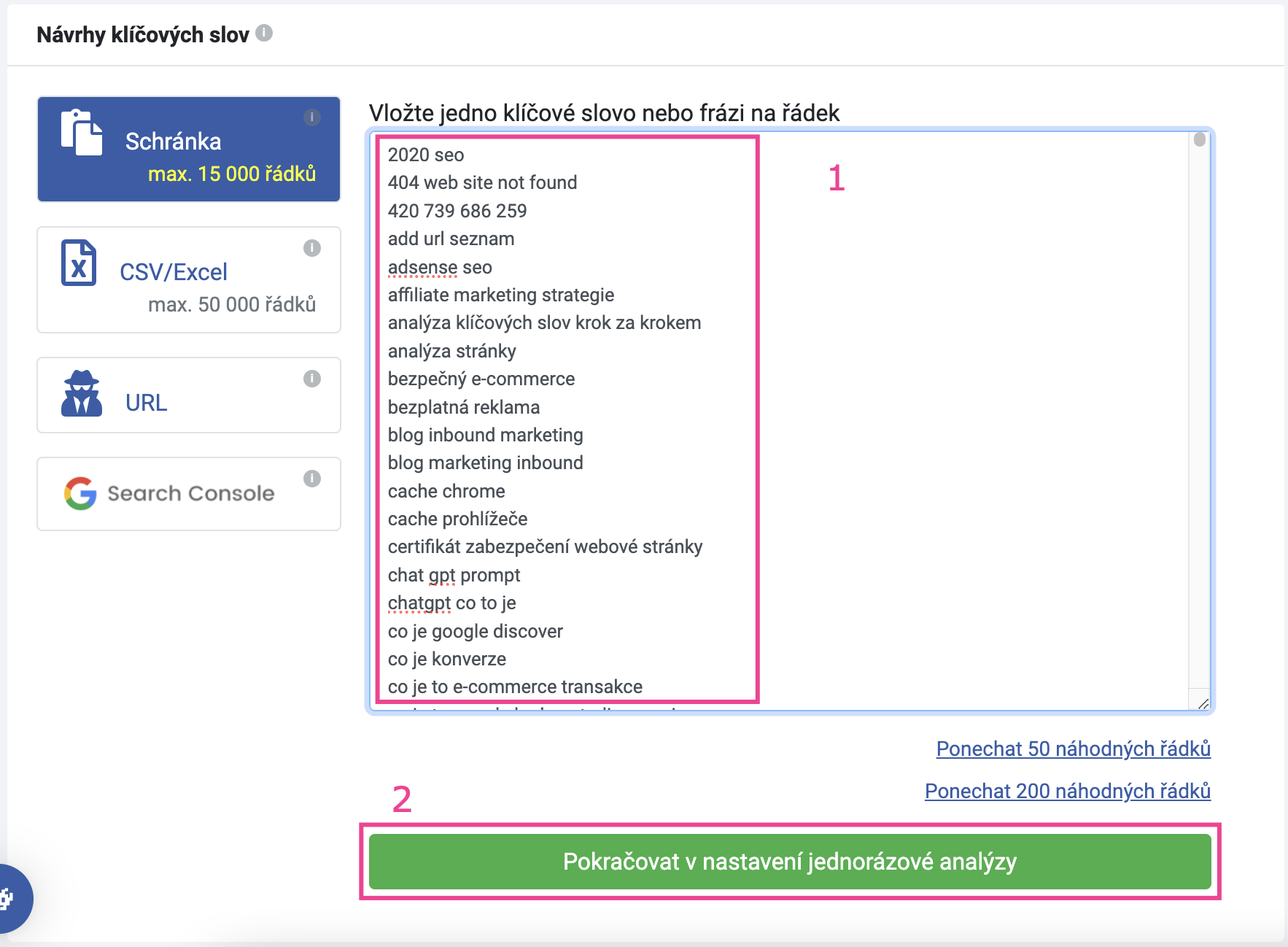
Zaškrtněte si zdroje, ze kterých si přejete získat návrhy slov (doporučujeme především vyhledávací okno a související dotazy z vyhledávačů).
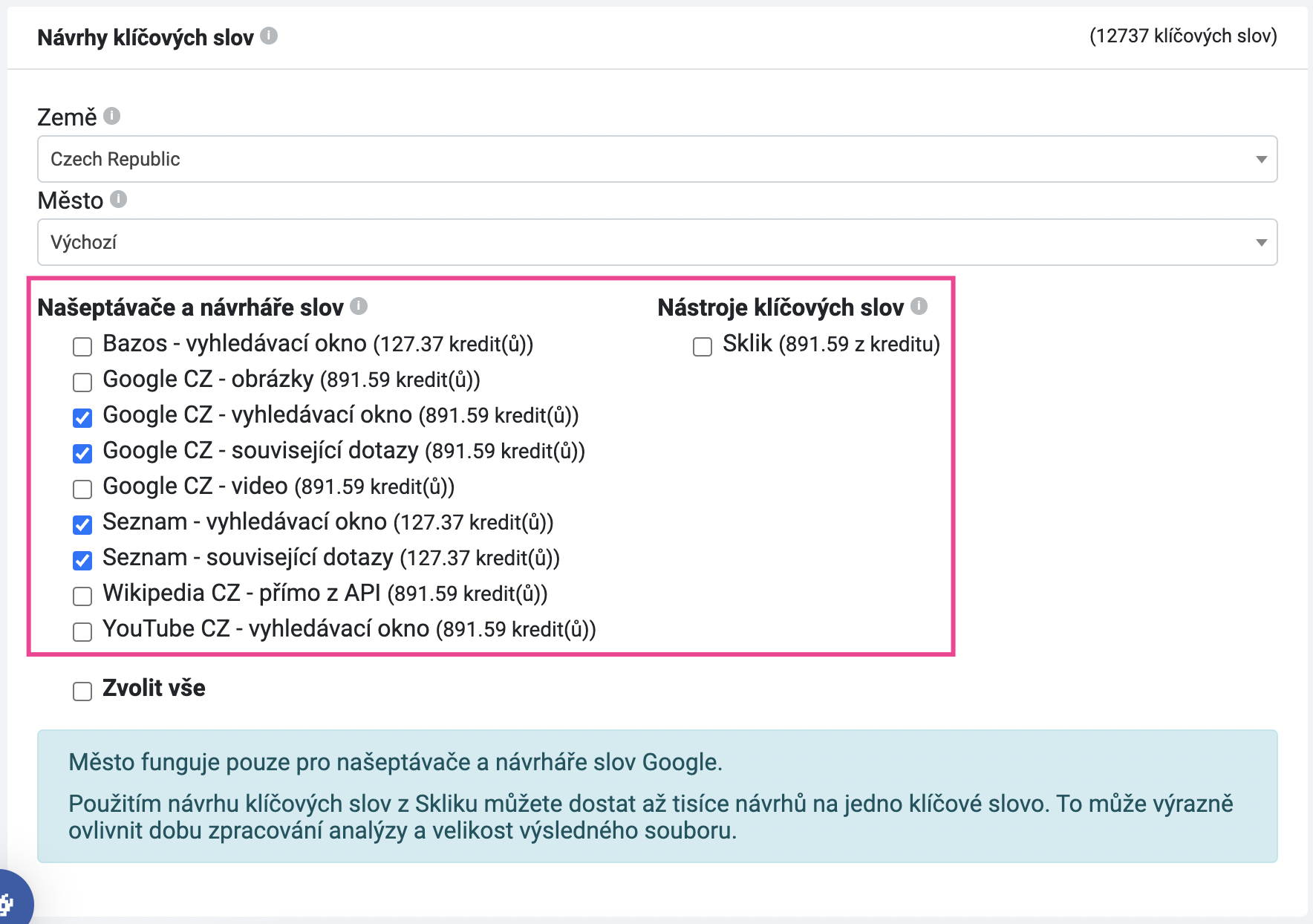
Ve spodní části nastavení spusťte analýzu.
V tuto chvíli vám analýza zpracuje všechna klíčová slova z vašeho datasetu a najde k nim adekvátní návrhy souvisejících výrazů. Tím pro svůj dataset získáte další klíčová slova.
Opět si stáhněte návrhy z analýzy do tabulky a tabulku otevřete.
Vyberte záložku Keywords.
![]()
V této tabulce vás nyní bude zajímat pouze sloupeček Suggest. Ostatní sloupečky případně můžete odstranit.
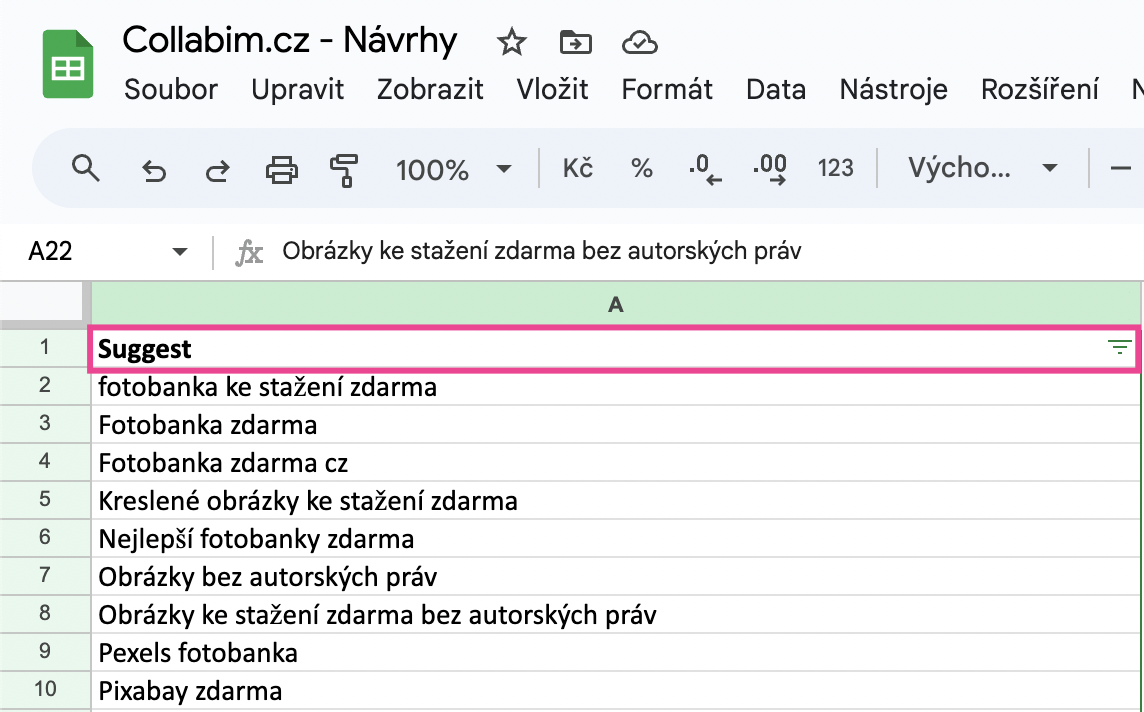
Odstranění duplicitních návrhů
Jelikož jsme v tomto případě použili několik zdrojů dat, je možné, že některé návrhy budou duplicitní. Ještě předtím, než sloučíme návrhy s původním datasetem, si návrhy očistíme od duplicit (aby nebylo nutné kopírovat zbytečně moc řádků).
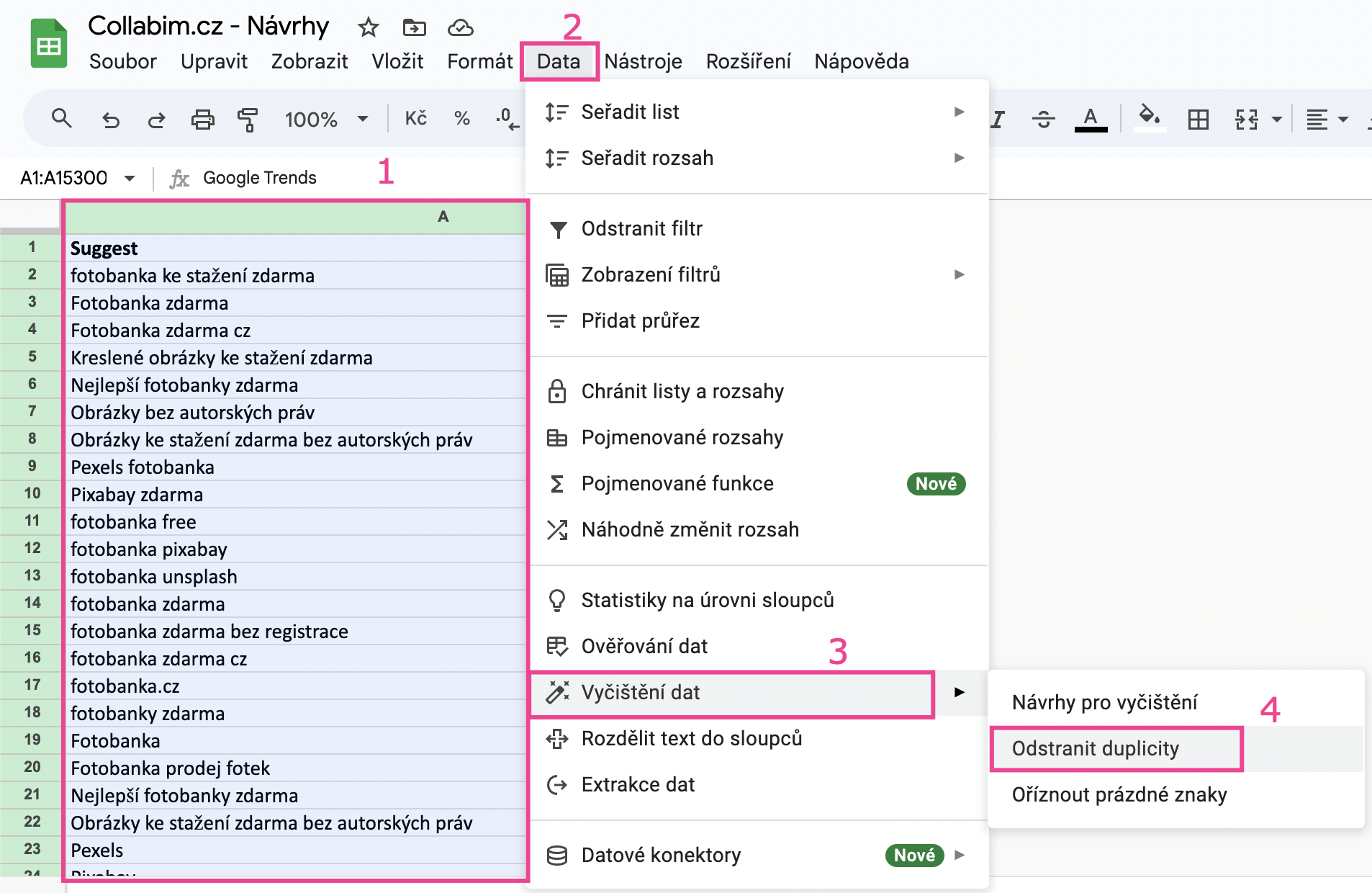
V tomto případě nám po očištění duplicit v tabulce zbylo okolo 85 tisíc výrazů z původních cca 153 tisíc.
I nyní se může stát, že po odstranění duplicit zůstanou v tabulce prázdné řádky. Postupujte proto stejným způsobem jako při odstranění prázdných řádků v předchozím případě.
Sloučení návrhů a datasetu
Nyní můžete sloučit klíčová slova z tabulky s návrhy s vaším datasetem.
Označte si všechna klíčová slova ve sloupečku Suggest a slova zkopírujte.
Zkopírované výrazy přidejte do svého původního datasetu. Opět odstraňte duplicity a zbavte se prázdných řádků. V našem případě jsme celkový počet okolo 105 tisíc výsledků stáhli na cca 98 tisíc.
Tím jste svůj základní dataset obohatili o související výrazy.
Zjištění pozic a hledanosti
Klíčová slova máte připravená, nyní je můžete prohnat analýzou Pozice a hledanost, abyste zjistili, jaký je objem hledání vašich frází a jaké na tyto fráze máte aktuálně pozice.
Doposud jsme totiž pracovali s různými typy analýz a kupříkladu analýza návrhy klíčových slov bohužel neměří hledanost ani pozice, tudíž je třeba váš dataset analyzovat ještě v separátní analýze.
Analýzu Pozice a hledanost najdete opět v hlavičce aplikace v sekci Analýzy a nástroje.
Naimportujte tabulku s vaším datasetem do analýzy a pokračujte k nastavení.
Poznámka:
Analýza umožňuje kvůli technickému omezení naimportovat pouze 50 000 řádků -> pokud vaše tabulka obsahuje více řádků, rozdělte obsah tabulky do více souborů a postup opakujte.
Jakmile se dostanete k nastavení analýzy, vyberte:
- změření pozic
- zjištění hledanosti
- a zadejte URL vašeho webu.
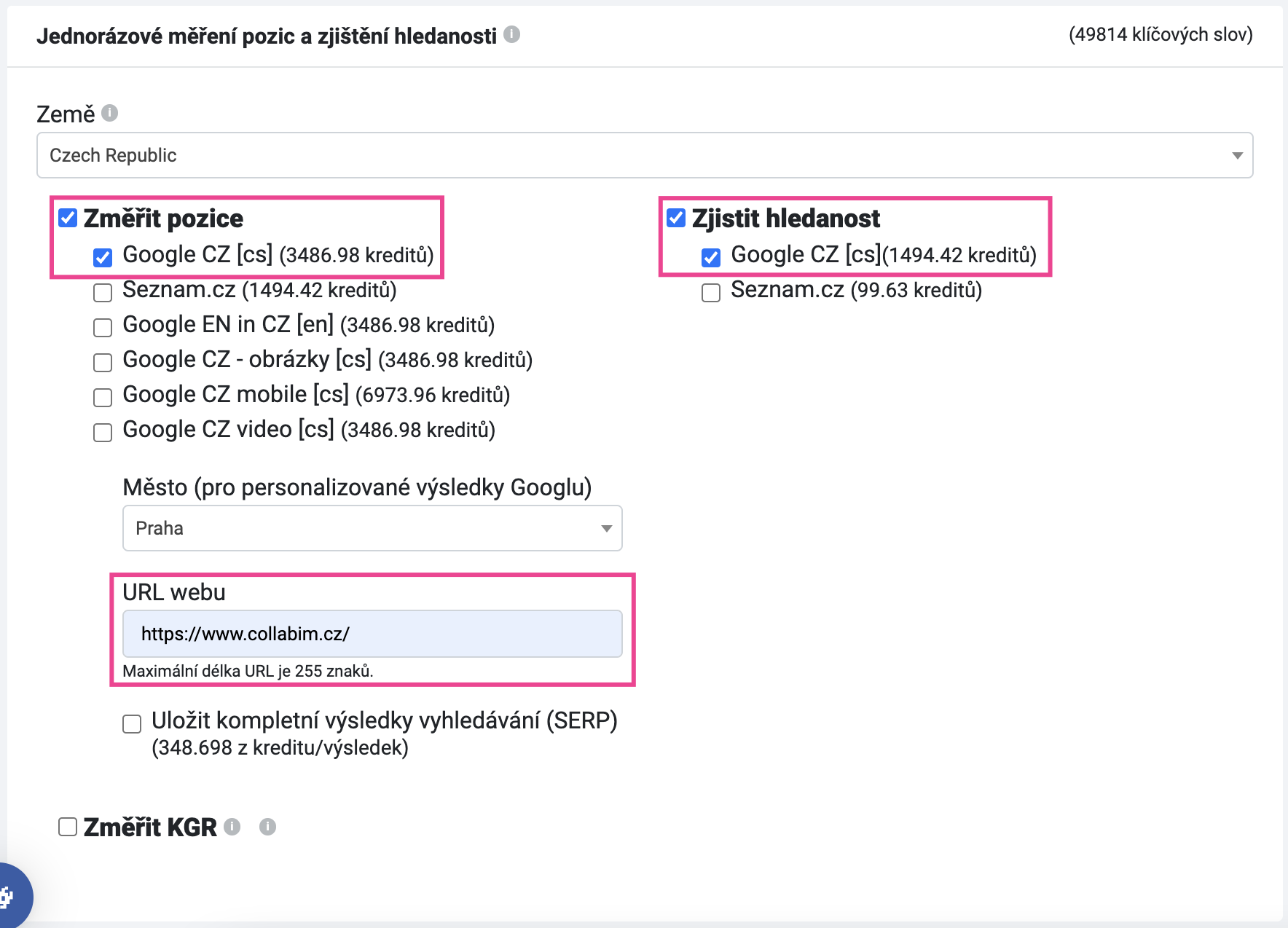
Nakonec jen spusťte analýzu a počkejte, až se analýza dokončí. Jakmile bude analýza hotova, opět ji stáhněte do tabulky a export otevřete v Tabulkách Google nebo Excelu.

Poznámka:
Pokud jste analýzu prováděli vícekrát kvůli většímu počtu řádků, kompletní výsledky obou analýz jednoduše slučte do jedné tabulky.
Nyní je dataset připraven – dále už můžete pracovat pouze s touto tabulkou. Dataset by v tuto chvíli měl obsahovat dostatek dat pro další práci – fráze z vašeho webu, konkurenčních webů a zároveň související dotazy včetně hledaností.
V tabulce si tak můžete filtrovat dle různých podmínek (zejména dle hledanosti) a používat ji k dalším procesům.
Můžete v ní např. vyhledat potenciální KGR kandidáty pro případné změření v rámci metody Keyword Golden Ratio. Nebo ji můžete využít jako vstupní data pro plnotučnou analýzu klíčových slov. Anebo tabulka může posloužit pro případný import klíčových slov do projektu, abyste je mohli pravidelně monitorovat.
V tuto chvíli by tabulka měla být opravdu bohatá na data, se kterými můžete pracovat dále.
